Python 图像教程
介绍
需要用到的软件
- Python 3+
- numpy
- matplotlib
- mahotas
- ipython¬ebook
第一个项目:计算细胞核
我们的第一个任务是进行细胞核的计算,你可以点击图像进行下载到本地跟着进行运行
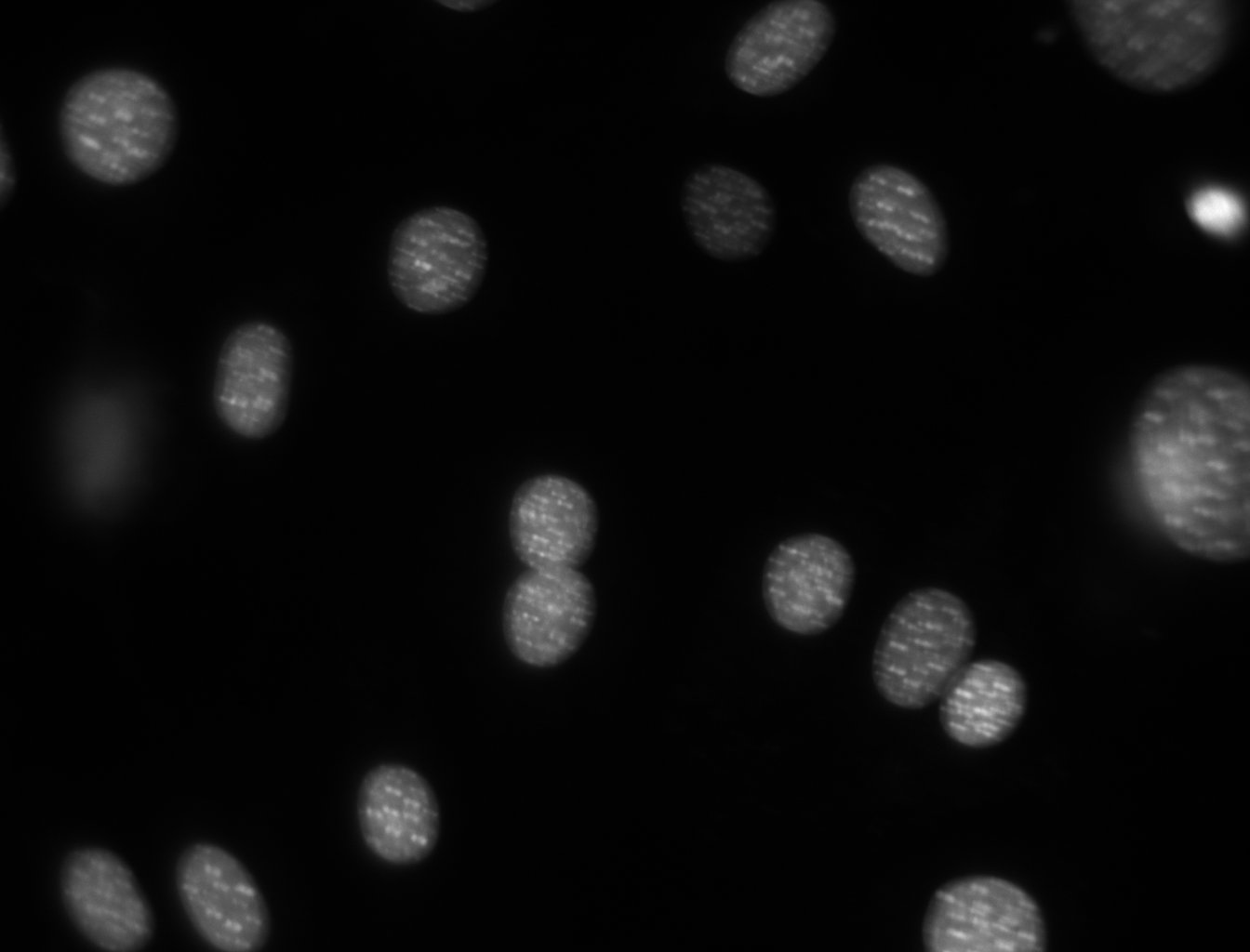 首先导入包
首先导入包
|
|
对于Python,有能够通过包来完成许多工具,而不是一个包。我们用numpy数组进行储存图像,在我们的案例中,其是一个二维数组(高X宽),或者,对于彩色图像,为三维数组(高X宽X3或者高X宽X4,其中3和4分别表示red,green,blue或者red,green,blue,alpha的元组,其中alpha为透明度) 首先我们读取图像进入内存:
|
|
玩弄
在交互模式,例如ipython,你可以查看使用如下方法查看图像
|
|
你可能惊讶图片并不像原来的图片是黑色的,原因是plt默认展示的为jet() bar,你可以通过切换colormap来切换成默认的灰度图,例如如下:
|
|
你还可以探索如下:
|
|
(1024, 1344)
uint8
252
0
|
|
我们将图片所有性质除以2,然而得到的结果居然一样,实际上plt在展示图片之前会进行对比扩展
一些实际的工作
现在我们开始实际的计算核酸的工作,我们对开篇导入的图片的物体(objects)进行计算
|
|

在这里,我们又一次利用了dna是一个numpy数组,并在逻辑运算中使用它(dna> T)的事实。 结果是一个布尔值的数组,这个pylab显示为一个黑白图像。 但是看起来不是那么美好,因为图像包含了许多小的物体。这里有两个方法解决它。一个简单的方法是使用Gaussian筛选抚平小的物体
|
|

mh.gaussian_filter接收图像并过滤器的标准偏差(以像素为单位)并返回过滤后的图像,但是一个更好的方法是使用mahotas筛选图像并且计算阈值,使用numpy操作创建的图像,并用plt展示他们,但是所有的工作都是数组完成的,这样的结果会更好。
我们现在进行一些细胞核的merged。 最后的计数只是一个额外的函数调用:
|
|
18
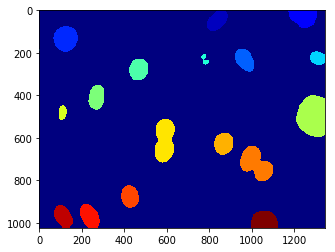
我们拥有物体的图像为18个,展示的为标记的(labeled)图像,使用jet()进行着色 我们可以探索标记的物体,其是一个整数的数组,它的值是该位置上对象的标签,所以值的范围从0(背景)到nr_objects。
第二个项目:分隔图像
通过第一个项目,我们完成的还是令人满意,但是仍然有一些核酸是黏在一起的,然我们to do better 这里有一个简单的,传统的想法:
- 平滑图像
- 寻找区域最大值
- 使用区域最大值作为watershed的种子
寻找种子
但是且慢,有一些细胞在照片上重叠了,被我们算作一个细胞了。显然是这不科学的,因此我们需要更精确的计算方法。接下来我们要讨论的方法寻找团块的中心点并计算中心点的个数。这里我们假设在灰度图上,团块比较中心的地方比较亮,最亮的地方就是最中心的地方。这个东西叫regional maxima,相当于一片山脉中的最高峰。我们找到这个点之后,进行标亮,并且与原来的灰度图重叠在一起。首先我们进行如下的尝试
|
|
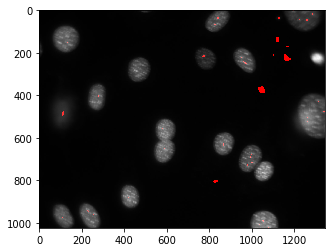
mh.overlay()返回一个彩色图像,第一个参数给出灰度级分量,而第二个参数作为红色通道。 结果看起来不太好:
稍微摆弄一下后,我们决定用一个更大的sigma尝试相同的想法:
|
|
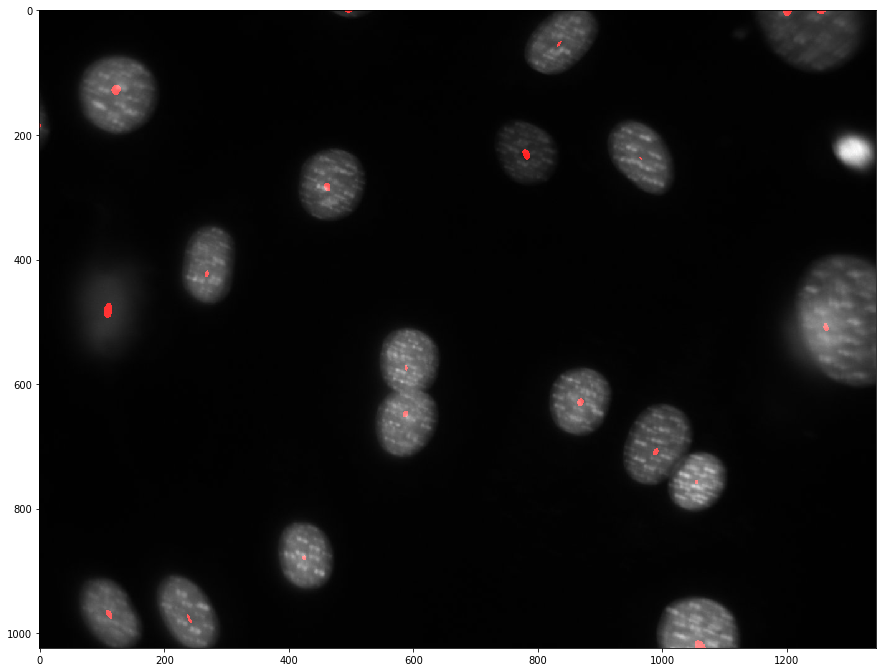
看起来好许多,我们可以方便的统计核算数量了
|
|
22
Watershed
我们打算将Watershed应用于阈值图像的距离变换(使用矩阵最大值减去矩阵内所有元素,使得矩阵元素的数值原来大的变小,小的变大,得到下图):
|
|

现在,根据矩阵的元素的大小,以之前得到的一堆最高峰(seeds)为核心位置,观察每个核心与邻居核心之间的边界(元素数值的局域极大值),把这个边界标记出来。就得到了核心的区域划分图。
|
|

参考资料: 原文 使用python做图像处理