SwissSimilarity是Swiss系提供的一个基于配体的虚拟筛选在线服务器。
主要的用途我觉得包含几个方面,1)一个是比如有一个小分子,需要找寻它潜在的靶标位点,作为一个找靶。2)另外一个是你有一个已知的靶点小分子,但是它的性能可能不好,你需要对其母环改造,那么可以进行骨架跃迁。3)还有一个应用就是你有一系列已知作用靶标的化合物,想找类似物进行合成优化,那么也可以进行LBVS进行初筛。当然限于我的知识面的原因,可能还有其他许多应用欢迎小伙伴们提出。
虚拟筛选(Virtual screening, VS)一般可以分为受体基础(RBVS)和配体基础(LBVS)两种方法,其中RBVS又可以称做结构为基础的虚拟筛选(SBVS),通常是对目标大分子进行对接筛选。LBVS则是通过分子相似性来和已知活性化合物相互比较。
分子描述方法简介
SwissSimilarity的工作则主要是基于LBVS方法,理论基础是相似性的分子拥有相似的生物活性,对于相似性的评判标准主要是通过分子描述,分子描述主要可以分为1维,2维或3维,三类(1D,2D,3D),下面主要介绍一下: 1D方法主要是1D-描述,如一些分子或者物理化学全局参数,例如分子体积,氢键供体/受体数量等等,其主要应用于数据库的清洗或者特别的项目标准(如:复合物可以跨越血脑屏障),SMINA教程以CDPK1为例中所提到的诱饵数据库Database of Useful Decoys:Enhanced(DUDE)也是使用该方法准备的(复合1D-描述,同时不符合2D-描述) 2D方法是用2维化学结构的性质来描述计算化学相似性,最有名的要数分子印迹(molecular fingerprints,FP),其将许多化学特征投射成简单的向量。FP2方法是一个典型的基于路径的FP方法,其分析给定数量键的分子结构所有片段的线性路径。FP之间的相似性的实际量化通常由Tanimoto系数给出,Tanimoto系数是两个字符串中常见正位的数量除以两个字符串之间的正位总数。 3D方法主要是考虑的分子的三维几何构象,包括药效团识别和形状相似性。一个3D优于2D方法的优势是可以用于骨架迁移的研究。由于3D方法计算时间较长,对于在线服务计算量大是不适宜这种在线网站做筛选的,所以SwissSimilarity对于3D方法选择的也是计算量比较小的一些方法,例如Spectrophores,其方法是把3D分子力场转换到1D描述。其包含48个向量,不仅包含形状的描述,同时也包含许多其他参数的描述。Electroshape-5D是采用的Gasteiger 部分电荷(在使用ucsf Dock时原始的电荷也是这个,小伙伴们有没有留意过呢)和原子分配系数(ALOGP)。当然这两种方法都不进行几何比对。3维的相似性量化最常用的方法为Tanimoto相关系数和Manhattan距离。
筛选数据库简介
SwissSimilarity包含许多小分子数据库,以下: 1)药物数据库,包含FDA批准的(1500),实验和在研的(4800,500),偏僻的(160),不正规的(illicit)(170)和营养品分子(78) 2)生物活性分子数据库,包括PDB(19500),高亲和力ChEBI数据库(28 000),来自ChEMBL和GLASS的酶和GPCR抑制剂数据库(480 000),生物代谢数据库HMDB(39 000) 3)ZINC 数据库 drug-like,lead-like 和 fragment-like (10 600 000, 4300 000,700 000),可以在供应商买到的(9700 000) 4)可合成的虚拟库(205万)
由于计算量的问题,有一些方法只适用于小的库,具体可以查看界面。
可用的筛选方法
其实上面已经介绍了,这里初略说一下:
- 2D相似性,基于相似结构的FP2分子印迹
- 3D相似性 Electroshape-5D和Spectrophore(见上文) Shape-IT和Align-IT分别基于3D形状和药效团 其中还有一个combined score,其英文的解释如下:
|
|
大致的意思是FP2和Electroshape-5D两种评分系统用逻辑回归拟合而成。
数据库使用
数据库的使用方法非常傻瓜
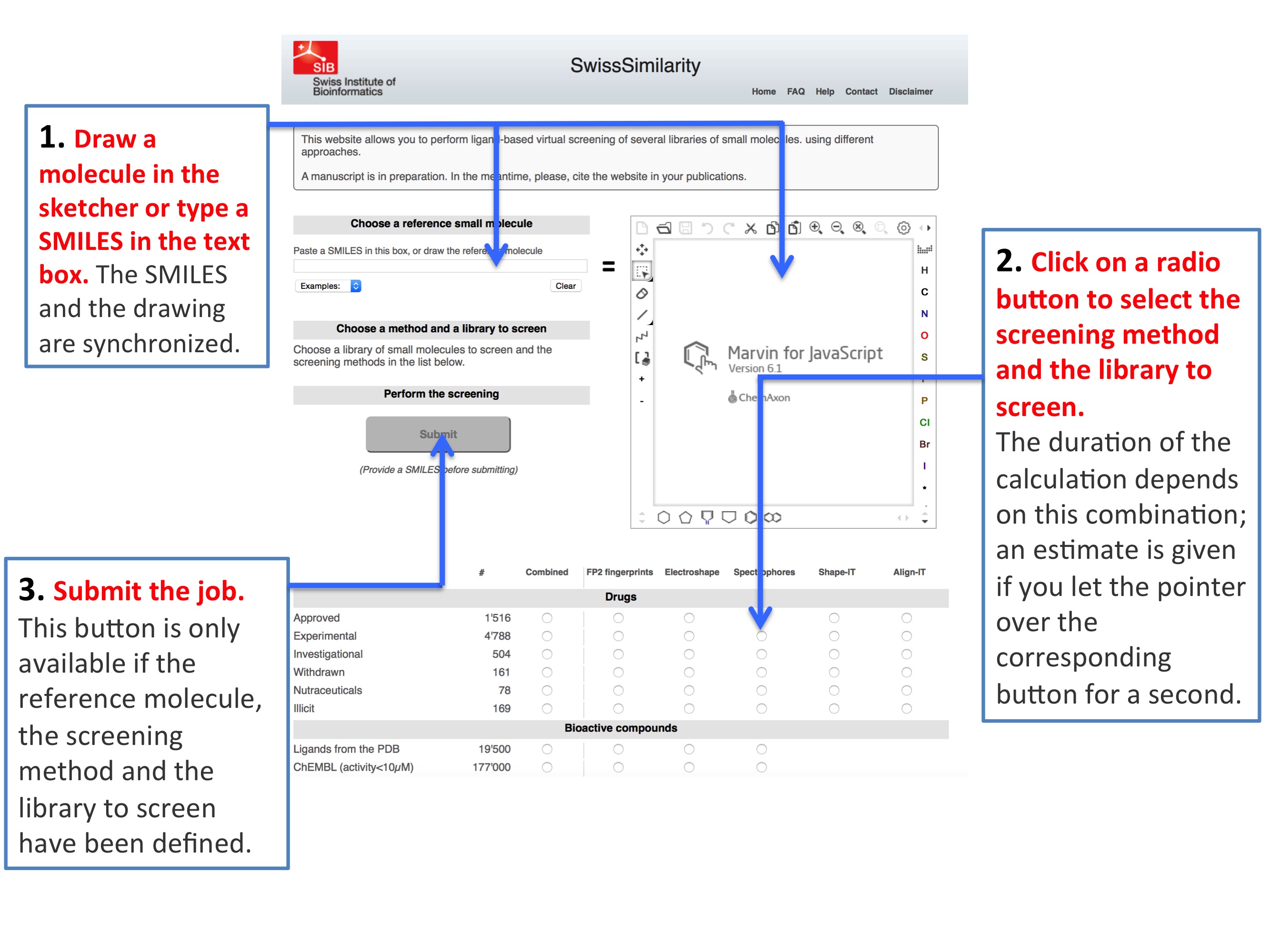
仅仅需要绘画或者输入SMILE选择要测的数据库提交
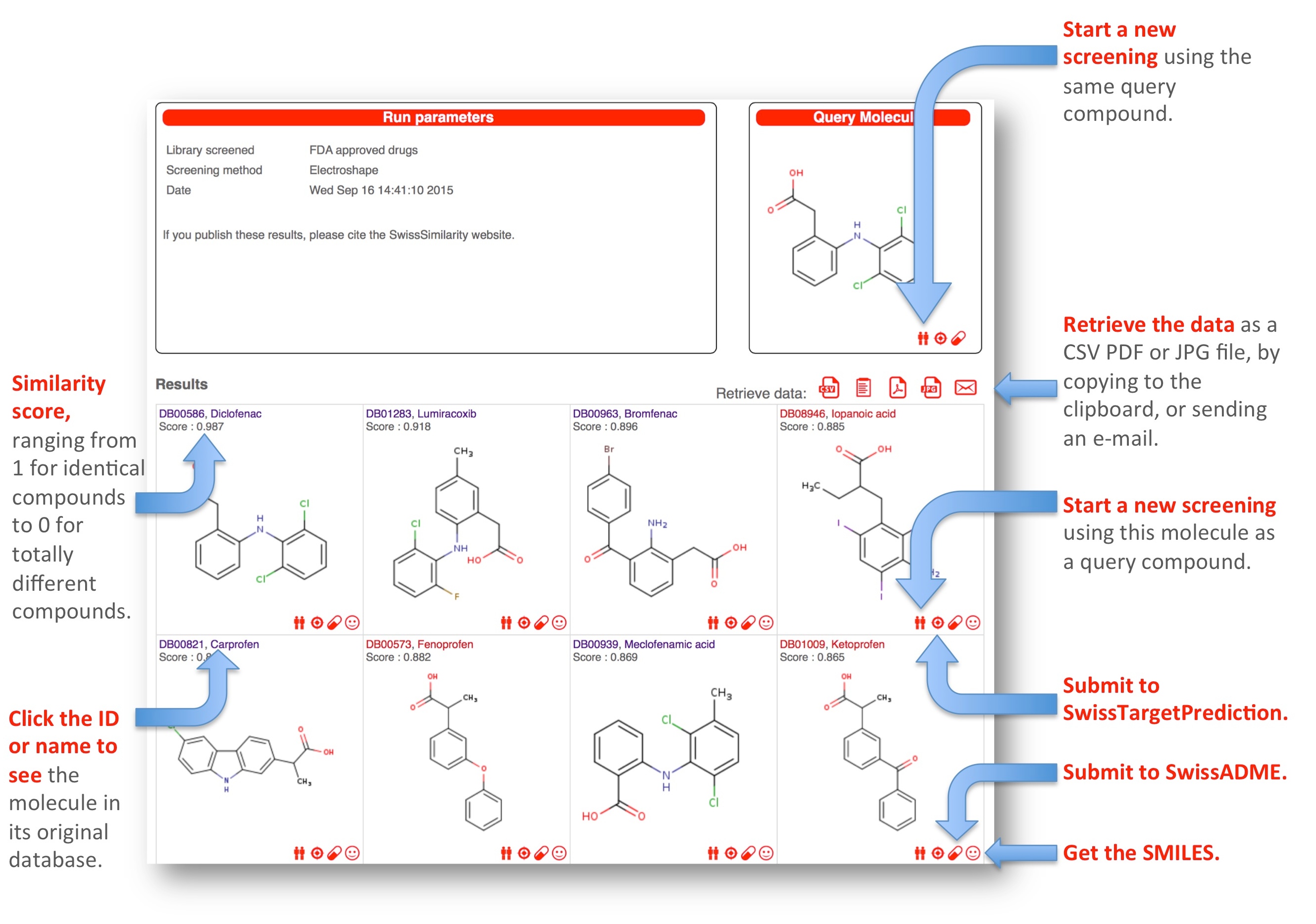
得出的配体按照打分排列,值为1为最相似,同时还整合了新虚拟筛选,靶标预测,ADME预测和获取SMILES功能
参考资料: Zoete, V., Daina, A., Bovigny, C., & Michielin, O. SwissSimilarity: A Web Tool for Low to Ultra High Throughput Ligand-Based Virtual Screening., J. Chem. Inf. Model., 2016, 56(8), 1399-1404. SwissSimilarity help